人工知能(AI)のディープラーニングを使って画像分類を行いました。ディープラーニングによる画像応用の代表的なモデルの一つとしてVGG16があります。VGG16の学習済みの畳み込みベースを用いて分類器を入れ替える転移学習という方法で、学習を行いました。
画像分類には5種類の花を使用しました。daisy、dandelion、rose、sunflower、tulipの5種類です。訓練データには、それぞれの花の画像を500枚ずつ、検証データには200枚ずつを使用しました。学習した結果の正解率は8割以上です。試しにsunflowerのテスト画像で予測してみたところ正解しています。
VGG16の転移学習を利用して画像を分類してみる
In [1]:
import os
import keras
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential, Model
from keras.layers import Input, Dense, Dropout, Activation, Flatten
from keras import optimizers
from keras.applications.vgg16 import VGG16
In [2]:
keras.__version__
Out[2]:
訓練画像、検証画像、テスト画像のディレクトリ
In [3]:
# 分類クラス
classes = ['daisy', 'dandelion','rose','sunflower','tulip']
nb_classes = len(classes)
batch_size_for_data_generator = 20
base_dir = "."
train_dir = os.path.join(base_dir, 'train_images')
validation_dir = os.path.join(base_dir, 'validation_images')
test_dir = os.path.join(base_dir, 'test_images')
train_daisy_dir = os.path.join(train_dir, 'daisy')
train_dandelion_dir = os.path.join(train_dir, 'dandelion')
train_rose_dir = os.path.join(train_dir, 'rose')
train_sunflower_dir = os.path.join(train_dir, 'sunflower')
train_tulip_dir = os.path.join(train_dir, 'tulip')
validation_daisy_dir = os.path.join(validation_dir, 'daisy')
validation_dandelion_dir = os.path.join(validation_dir, 'dandelion')
validation_rose_dir = os.path.join(validation_dir, 'rose')
validation_sunflower_dir = os.path.join(validation_dir, 'sunflower')
validation_tulip_dir = os.path.join(validation_dir, 'tulip')
test_daisy_dir = os.path.join(test_dir, 'daisy')
test_dandelion_dir = os.path.join(test_dir, 'dandelion')
test_rose_dir = os.path.join(test_dir, 'rose')
test_sunflower_dir = os.path.join(test_dir, 'sunflower')
test_tulip_dir = os.path.join(test_dir, 'tulip')
# 画像サイズ
img_rows, img_cols = 200, 200
画像データの数を確認する
In [4]:
print('total training daisy images:', len(os.listdir(train_daisy_dir)),train_daisy_dir)
print('total training dandelion images:', len(os.listdir(train_dandelion_dir)),train_dandelion_dir)
print('total training rose images:', len(os.listdir(train_rose_dir)),train_rose_dir)
print('total training sunflower images:', len(os.listdir(train_sunflower_dir)),train_sunflower_dir)
print('total training tulip images:', len(os.listdir(train_tulip_dir)),train_tulip_dir)
print('total validation daisy images:', len(os.listdir(validation_daisy_dir)),validation_daisy_dir)
print('total validation dandelion images:', len(os.listdir(validation_dandelion_dir)),validation_dandelion_dir)
print('total validation rose images:', len(os.listdir(validation_rose_dir)),validation_rose_dir)
print('total validation sunflower images:', len(os.listdir(validation_sunflower_dir)),validation_sunflower_dir)
print('total validation tulip images:', len(os.listdir(validation_tulip_dir)),validation_tulip_dir)
print('total test daisy images:', len(os.listdir(test_daisy_dir)),test_daisy_dir)
print('total test dandelion images:', len(os.listdir(test_dandelion_dir)),test_dandelion_dir)
print('total test rose images:', len(os.listdir(test_rose_dir)),test_rose_dir)
print('total test sunflower images:', len(os.listdir(test_sunflower_dir)),test_sunflower_dir)
print('total test tulip images:', len(os.listdir(test_tulip_dir)),test_tulip_dir)
ImageDataGeneratorを使って画像データを拡張する
In [5]:
train_datagen = ImageDataGenerator(rescale=1.0 / 255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)
train_generator = train_datagen.flow_from_directory(directory=train_dir,target_size=(img_rows, img_cols),color_mode='rgb',classes=classes,class_mode='categorical',batch_size=batch_size_for_data_generator,shuffle=True)
In [6]:
test_datagen = ImageDataGenerator(rescale=1.0 / 255)
validation_generator = test_datagen.flow_from_directory(directory=validation_dir,target_size=(img_rows, img_cols),color_mode='rgb',classes=classes,class_mode='categorical',batch_size=batch_size_for_data_generator,shuffle=True)
VGG16モデル
In [7]:
input_tensor = Input(shape=(img_rows, img_cols, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
vgg16.summary()
VGG16モデルに全結合分類器を追加する
In [8]:
top_model = Sequential()
#model.add(vgg16)
#model.add(Flatten())
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(nb_classes, activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
model.summary()
VGG16のblock5_conv1以降と追加した全結合分類器のみ訓練する
In [9]:
vgg16.trainable = True
set_trainable = False
for layer in vgg16.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
In [10]:
for layer in vgg16.layers:
print(layer, layer.trainable )
In [11]:
for layer in model.layers:
print(layer, layer.trainable )
In [12]:
model.compile(loss='categorical_crossentropy',optimizer=optimizers.RMSprop(lr=1e-5), metrics=['acc'])
学習
In [13]:
history = model.fit_generator(train_generator,steps_per_epoch=25,epochs=30,validation_data=validation_generator,validation_steps=10,verbose=1)
学習結果を保存する
In [14]:
hdf5_file = os.path.join(base_dir, 'flower-model.hdf5')
model.save_weights(hdf5_file)
学習推移をグラフに表示する
In [15]:
import matplotlib.pyplot as plt
In [16]:
%matplotlib inline
In [17]:
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

訓練データと検証データでの正解率
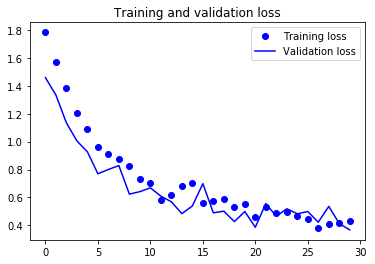
訓練データと検証データでの損失値
テストの画像データで正解率を調べる
In [18]:
test_generator = test_datagen.flow_from_directory(directory=test_dir,target_size=(img_rows, img_cols),color_mode='rgb',classes=classes,class_mode='categorical',batch_size=batch_size_for_data_generator)
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test acc:', test_acc)
実際にテスト画像を分離してみる
In [19]:
import numpy as np
from keras.preprocessing.image import load_img, img_to_array
from keras.applications.vgg16 import preprocess_input
In [20]:
filename = os.path.join(test_dir, 'sunflower')
filename = os.path.join(filename, '3681233294_4f06cd8903.jpg')
filename
Out[20]:
In [21]:
from PIL import Image
In [22]:
img = np.array( Image.open(filename))
plt.imshow( img )
Out[22]:

テストデータ
In [23]:
img = load_img(filename, target_size=(img_rows, img_cols))
x = img_to_array(img)
x = np.expand_dims(x, axis=0)
predict = model.predict(preprocess_input(x))
for pre in predict:
y = pre.argmax()
print("test result=",classes[y], pre)